Formation
Apache Airflow
Créer, planifier et surveiller
des workflows programmatiques
7 modules · ~7-10 heures · De l'introduction aux pipelines SQL
Créer, planifier et surveiller
des workflows programmatiques
7 modules · ~7-10 heures · De l'introduction aux pipelines SQL
Découvrir Airflow, son architecture et les concepts fondamentaux
| Problème avec les cron jobs | Solution Airflow |
|---|---|
| Pas de visibilité sur l'état des tâches | Interface web avec statuts en temps réel |
| Pas de gestion des dépendances | Les DAGs définissent l'ordre d'exécution |
| Pas de gestion des erreurs | Retries automatiques, callbacks d'alerte |
| Configuration dispersée (crontab) | Tout en Python, versionné avec Git |
| Pas de logs centralisés | Logs par tâche, accessibles dans l'interface |
Extraire, transformer et charger des données depuis de multiples sources
Entraînement, évaluation et déploiement de modèles de Machine Learning
Sauvegardes, nettoyage de fichiers, gestion de serveurs Cloud
Requêtes SQL planifiées, génération Excel, envoi par email
Le cœur de la mémoire d'Airflow. Généralement PostgreSQL ou MySQL.
Le cerveau du système. Il tourne en permanence et :
~/airflow/dags/)L'Executor détermine comment et où les tâches s'exécutent. Les Workers exécutent réellement le code.
| Executor | Description | Usage |
|---|---|---|
SequentialExecutor | Une seule tâche à la fois | Tests uniquement |
LocalExecutor | Parallèle, même machine | Petites installations |
CeleryExecutor | Répartit sur plusieurs serveurs | Production distribuée |
KubernetesExecutor | Un conteneur éphémère par tâche | Production Cloud |
Interface graphique basée sur Flask / Gunicorn.
Gère les tâches asynchrones (Deferrable Operators).
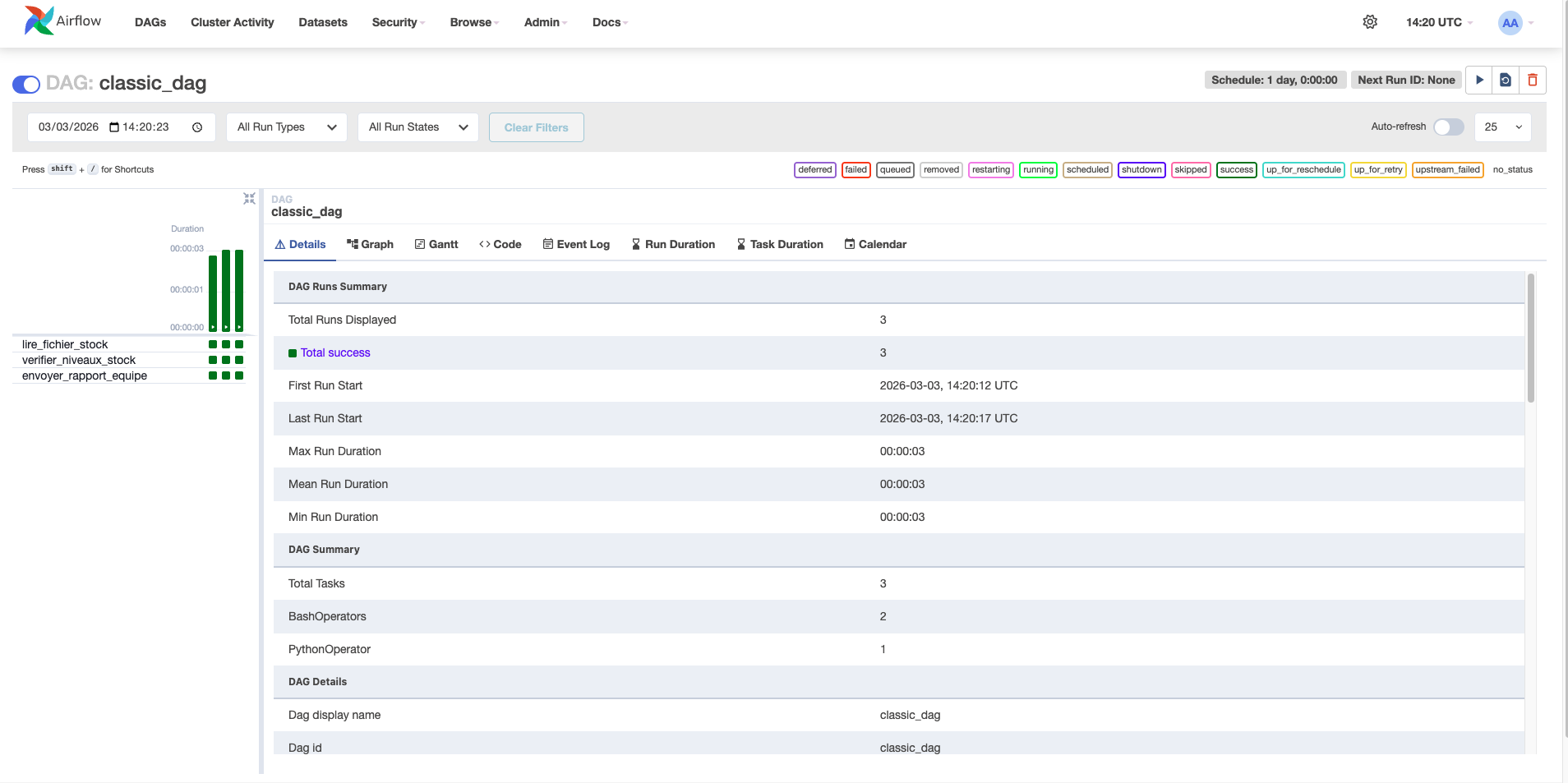
Le tableau de bord principal. Pour chaque DAG, vous voyez :
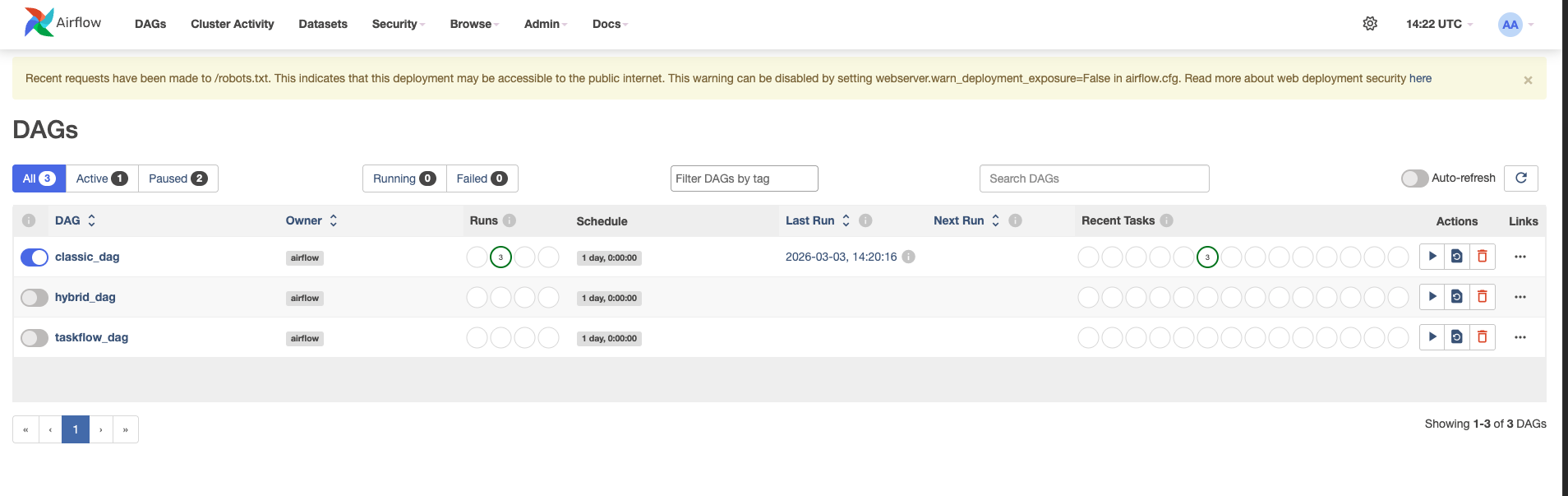
La vue la plus utilisée pour surveiller l'historique. Colonnes = exécutions dans le temps, Lignes = tâches du DAG.
Chaque case de la grille indique le statut d'une tâche pour un run donné.
| Couleur | Statut | Signification |
|---|---|---|
| Vert | success | Tâche terminée avec succès |
| Rouge | failed | Toutes les tentatives épuisées, échec définitif |
| Orange foncé | running | Tâche en cours d'exécution |
| Orange moyen | up_for_retry | En attente avant une nouvelle tentative |
| Orange clair | upstream_failed | Une tâche en amont a échoué |
| Bleu | queued | En file d'attente, attend un worker |
| Gris | skipped | Ignorée volontairement (ex : branche non choisie) |
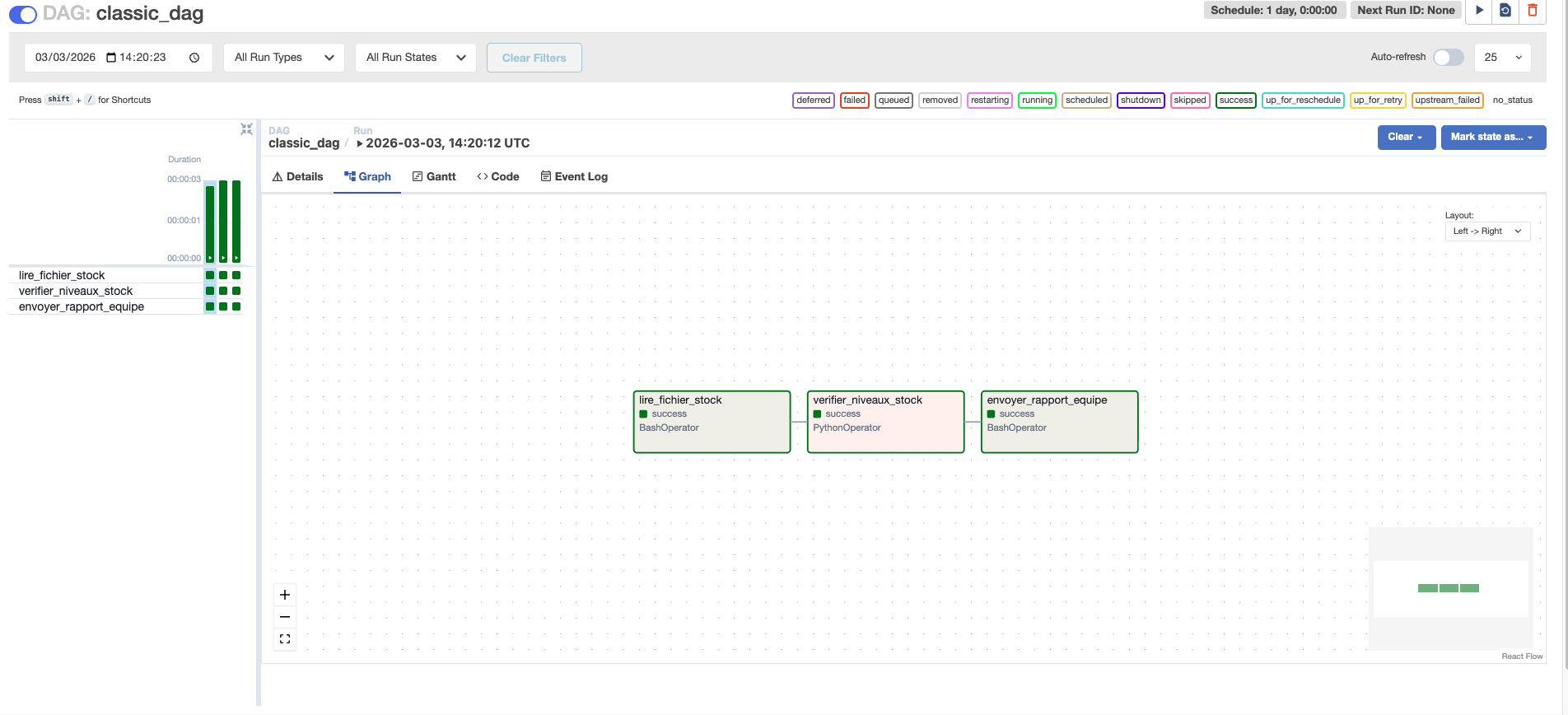
Structure logique du DAG : les tâches sous forme de cases reliées par des flèches. Idéal pour comprendre l'ordre d'exécution et le parallélisme.
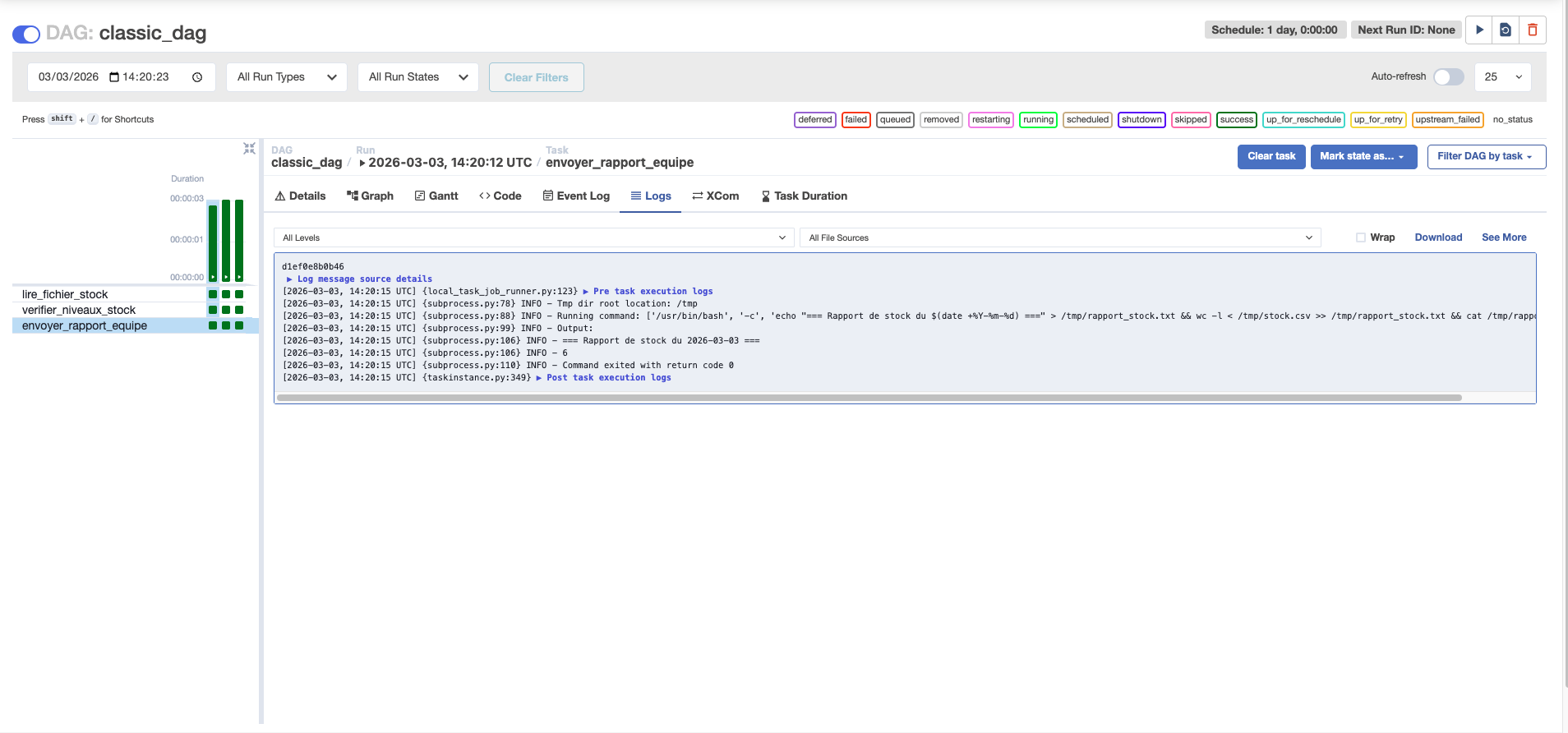
Outil n°1 pour le débogage. Cliquez sur une tâche → onglet Log → sortie console complète.
Directed Acyclic Graph (Graphe Orienté Acyclique)
Un Opérateur est un modèle de tâche prédéfini. Chaque opérateur nécessite au minimum un task_id unique et un ou plusieurs paramètres spécifiques à son type.
BashOperator et PythonOperator sont les fondamentaux, mais Airflow propose un large catalogue d'opérateurs spécialisés :
| Opérateur | Ce qu'il fait | Cas d'usage |
|---|---|---|
SQLExecuteQueryOperator | Exécute une requête SQL | Pipelines de données |
EmailOperator | Envoie un email | Notifications, rapports |
SlackAPIPostOperator | Poste un message Slack | Alertes d'équipe |
SimpleHttpOperator | Appelle une API HTTP | Intégrations tierces |
BranchPythonOperator | Choisit un chemin conditionnel | Flux dynamiques (Module 2) |
template_fields — on y reviendra dans le Module 4 (Jinja Templating).
>>Si task_2 échoue → task_3 ne démarre pas (statut Upstream Failed)
Airflow propose trois syntaxes pour définir un pipeline. Chacune a ses avantages selon le contexte.
with DAG(...):
@dag + @task
La méthode historique : with DAG(...) as dag: ouvre le conteneur, puis on déclare chaque opérateur en dessous.
>>La méthode recommandée depuis Airflow 2.0 pour du Python pur. Les dépendances sont implicites : Airflow déduit l'ordre via les arguments des fonctions.
return automatiqueMélanger opérateurs classiques et @task dans un même DAG — idéal pour une migration progressive.
@task doit être appelée python_step() avant de pouvoir la chaîner avec >>. Sans les parenthèses, c'est une fonction, pas une tâche.
| Classique | TaskFlow | Hybride | |
|---|---|---|---|
| Déclaration | with DAG(...): | @dag | @dag |
| Tâches | BashOperator, PythonOperator | @task | Les deux |
| Dépendances | Explicites (>>) | Implicites (flux de données) | Explicites (>>) |
| Données | XComs manuels | return automatique | Mixte |
| Quand ? | Pipelines existants | Nouveau code Python | Migration progressive |
Branchements, groupes de tâches et sensors
Exécuter des chemins différents selon une condition — comme un if/else au niveau du DAG.
task_id (str) ou une liste de task_id pour activer plusieurs branches simultanément : return ['notifier_client', 'notifier_support']
Depuis Airflow 2.0, préférez le décorateur @task.branch au BranchPythonOperator — plus concis et cohérent avec l'API TaskFlow.
@task.branch pour tout nouveau code.
Après un branchement, la tâche de convergence ne s'exécutera jamais par défaut (all_success) car une branche est toujours skippée.
trigger_rule='all_success'trigger_rule='none_failed_min_one_success'Regrouper des tâches dans des boîtes repliables dans l'UI — purement visuel, sans impact sur l'exécution.
task_id préfixés : validation.vérifier_stock
Vous rencontrerez peut-être des SubDagOperator dans du code existant. Ce mécanisme permettait d'imbriquer un DAG entier à l'intérieur d'un autre.
| SubDAG | TaskGroup | |
|---|---|---|
| Statut | Déprécié | Recommandé |
| Exécution | Worker dédié (risque deadlock) | Workers normaux |
| Visibilité | DAG séparé caché | Boîte repliable dans le même DAG |
| Complexité | Élevée (fichier/fonction séparés) | Faible (with TaskGroup():) |
Opérateurs qui attendent qu'une condition externe soit remplie avant de continuer.
Identité, planification, concurrence et configuration dynamique
dag_id — Unique, descriptif. Deux DAGs avec le même ID = conflit silencieuxtags — Badges cliquables pour filtrer la liste des DAGsdefault_args — S'applique à toutes les tâches, surchargeable individuellementDeux paramètres essentiels : start_date (à partir de quand) et schedule_interval (à quelle fréquence).
schedule_interval — Cronschedule_interval — Presets| Preset | Fréquence |
|---|---|
@daily | Tous les jours minuit |
@hourly | Toutes les heures |
@weekly | Dimanche minuit |
None | Manuel uniquement |
catchup=False — Si votre start_date est dans le passé, Airflow lance par défaut tous les runs manqués d'un coup. Cela peut saturer votre serveur. Désactivez-le sauf besoin explicite.
Limiter le parallélisme pour protéger les ressources ou faciliter le debug.
| Paramètre | Portée | Effet |
|---|---|---|
max_active_runs | Le DAG entier | Nombre de DAGRuns simultanés |
max_active_tasks | Un seul DAGRun | Nombre de tâches parallèles dans un run |
Utilisez la vue Gantt pour observer l'effet du parallélisme.
Valeurs modifiables via le formulaire "Trigger DAG w/ config". Portée : un seul DAGRun.
@task)Paires clé-valeur stockées dans Admin > Variables. Persistantes, partagées entre tous les DAGs.
Dans l'interface : Admin > Variables > +
| Key | Val |
|---|---|
chemin_source | /data/ventes/ |
config_pipeline | {"seuil": 5} |
@task)Variable.get() au top level du fichier — le scheduler relit les fichiers toutes les 30s, provoquant une requête DB à chaque fois. Appelez-le dans une fonction de tâche.
params | Variable | |
|---|---|---|
| Portée | Un seul DAGRun | Globale (tous les DAGs) |
| Stockage | Configuration du run | Base de données Airflow |
| Modification | Formulaire au déclenchement | Admin > Variables |
| Accès Python | context['params']['x'] | Variable.get('x') |
| Cas d'usage | Overrides ponctuels, tests | Config globale (chemins, emails, seuils) |
Injecter des valeurs dynamiques dans vos tâches
Jusqu'ici, vos tâches utilisaient des valeurs en dur. En production, un pipeline doit adapter ses valeurs au contexte d'exécution : chemins datés, requêtes SQL filtrées par période, messages dynamiques.
Valeur en dur — il faut modifier le code à chaque exécution
Remplacé automatiquement par la date logique du run
Syntaxe {{ ... }} — remplacée au moment de l'exécution de la tâche, pas au chargement du fichier par le scheduler.
On pourrait écrire datetime.now() dans un PythonOperator. Mais cela pose deux problèmes :
Renvoie la date réelle d'exécution, pas la date logique du run. En cas de rattrapage ou relance, vous obtenez la mauvaise date.
Ces opérateurs n'exécutent pas de Python — le templating Jinja est le seul moyen d'y injecter des valeurs dynamiques.
Dans le module précédent, on accédait aux params et variables en Python. Le templating Jinja permet de les injecter directement dans les champs des opérateurs.
template_fields — Le templating ne fonctionne que dans certains champs de l'opérateur (bash_command, sql…). Vérifiez avec : print(BashOperator.template_fields)
Au-delà des params et variables, Airflow injecte automatiquement les informations du contexte d'exécution.
| Variable | Description | Exemple |
|---|---|---|
{{ ds }} | Date logique (YYYY-MM-DD) | 2024-03-15 |
{{ ds_nodash }} | Date logique sans tirets | 20240315 |
{{ ts }} | Timestamp complet ISO 8601 | 2024-03-15T00:00:00+01:00 |
{{ data_interval_start }} | Début de la période traitée | 2024-03-15T00:00:00+01:00 |
{{ data_interval_end }} | Fin de la période traitée | 2024-03-16T00:00:00+01:00 |
| Variable | Description |
|---|---|
{{ dag.dag_id }} | ID du DAG courant |
{{ task_instance.task_id }} | ID de la tâche en cours |
{{ params.xxx }} | Paramètre du DAG (Module 3) |
{{ var.value.xxx }} | Variable Airflow (Module 3) |
Transforment une valeur avec le pipe |
Fonctions appelées dans les {{ }}
Le paramètre user_defined_macros du DAG permet de définir vos propres variables et fonctions accessibles dans les templates — sans préfixe.
Fuseaux horaires, changement d'heure, intervalle de données et catchup
pendulumSans fuseau horaire, 0 8 * * * = 8h UTC = 9h en hiver ou 10h en été à Paris.
tz="Europe/Paris", Airflow interprète le cron comme 8h heure de Paris et gère CET/CEST automatiquement.
2h → 3h : la plage 2h-3h n'existe pas
Un DAG planifié à 2h30 → ne tourne pas
3h → 2h : la plage 2h-3h se produit 2 fois
Un DAG planifié à 2h30 → peut tourner 2 fois
| Format | Comportement au changement d'heure |
|---|---|
Cron "0 8 * * *" | Suit l'heure locale — toujours 8h Paris |
timedelta(hours=24) | Compte exactement 24h — décale d'une heure |
Chaque run traite une période, pas un instant. Un DAG quotidien du 1er janvier ne tourne pas le 1er — il tourne le 2 janvier pour traiter les données du 1er.
| Période traitée | logical_date (= ds) | Moment réel du run |
|---|---|---|
| 01 jan → 02 jan | 2024-01-01 | 2 janvier 00:00 |
| 02 jan → 03 jan | 2024-01-02 | 3 janvier 00:00 |
| 03 jan → 04 jan | 2024-01-03 | 4 janvier 00:00 |
{{ ds }} au lieu de datetime.now() — un run relancé traite toujours les mêmes données.
| Catchup | Backfill | |
|---|---|---|
| Déclenchement | Automatique à l'activation | Manuel via CLI |
| Périmètre | Tout depuis start_date | Plage choisie |
| Ordre | Tous en parallèle | Chronologique |
| Risque | Surcharge massive | Maîtrisé |
| Usage | Quasi jamais | Après correction de bug |
Retries, alertes, interventions manuelles et règles de déclenchement
La plupart des erreurs sont transitoires (coupure réseau, API 503). Les retries les absorbent automatiquement.
Méthode la plus simple : Airflow envoie un email automatiquement après un échec définitif (retries épuisés).
airflow.cfg (section [smtp]).
Pour Slack, Teams ou tout webhook : on_failure_callback reçoit un dictionnaire context avec toutes les infos sur l'échec.
| Clé | Contenu |
|---|---|
context['dag'].dag_id | ID du DAG |
context['task_instance'].task_id | ID de la tâche |
context['execution_date'] | Date logique (datetime) |
context['ds'] | Date logique (str) |
context['exception'] | L'erreur qui a causé l'échec |
DAG(on_failure_callback=send_alert)
BashOperator(..., on_failure_callback=fn)
Un SLA (Service Level Agreement) définit le temps maximum qu'une tâche devrait mettre. Si ce délai est dépassé, Airflow déclenche une alerte — mais n'arrête pas la tâche.
dagrun_timeout — Le SLA alerte sans interrompre, tandis que dagrun_timeout tue le DAGRun entier. Utilisez les deux ensemble pour surveiller puis couper si nécessaire.
Dans Airflow, on ne "relance" pas — on efface l'état. La tâche revient dans la file et Airflow la relance.
Par défaut, une tâche exige que toutes ses tâches amont aient réussi (all_success). Mais ce comportement est parfois trop strict :
| Trigger Rule | S'exécute si… | Cas d'usage |
|---|---|---|
all_success | Toutes amont ont réussi | Défaut, pipeline linéaire |
one_success | ≥1 amont a réussi | Rapport partiel tolérant |
all_done | Toutes terminées (peu importe le résultat) | Nettoyage, libération de ressources |
none_failed_min_one_success | Aucun échec + ≥1 succès | Convergence après branchement |
always | Toujours | Logging, métriques |
Airflow adopte une stratégie de dégradation progressive. Avant d'alerter un humain, il essaie de se débrouiller seul.
retry_delay, réessaie jusqu'à retries fois
on_failure_callback
Connections, opérateurs SQL, XComs et pipelines complets
C'est la distinction la plus importante à retenir sur Airflow.
Un coffre-fort centralisé pour les identifiants, accessible via Admin > Connections.
Supporte nativement : PostgreSQL, MySQL, SQLite, Snowflake, BigQuery, S3, HTTP…
Exécute du SQL via un conn_id, avec support complet du templating Jinja.
sql est templatisable : WHERE date = '{{ ds }}';.sql externeXCom = mécanisme pour transmettre des valeurs entre tâches d'un même DAGRun. Stocké dans la base de données interne d'Airflow, visible dans Admin > XComs.
@task : le return est automatiquement stockéSQLExecuteQueryOperator : le résultat du SELECT est stockéti.xcom_push(key, value)@task : passer le résultat en argument.output : pont entre opérateur classique et @taskti.xcom_pull(task_ids='...')SELECT est une liste de tuples : [(1249.94,)]. Pour extraire la valeur : total[0][0] (première ligne, première colonne).
Par défaut, une @task produit un seul XCom (clé return_value). Avec multiple_outputs=True, chaque clé du dictionnaire retourné devient un XCom séparé.
Deux façons de manipuler les XComs selon le type de tâche.
TaskFlow (@task) | Opérateur classique | |
|---|---|---|
| Produire | return valeur | Automatique (ex: résultat SELECT) ou ti.xcom_push(key, val) |
| Récupérer | Passer en argument : fn(result) | .output ou ti.xcom_pull(task_ids='...') |
| Multi-valeurs | multiple_outputs=True | Plusieurs xcom_push avec des clés différentes |
| Pont entre les deux | fn(operateur.output) — passe le XCom d'un opérateur à une @task | |
| Via Jinja | {{ ti.xcom_pull(task_ids='...', key='...') }} — dans tout champ templatisable | |
CREATE TABLE IF NOT EXISTS — Idempotent, relançable sans erreur{{ ds }} dans l'INSERT — Chaque run insère avec sa propre date logique{{ ds }} dans le WHERE — Chaque run ne lit que ses propres données.output — Pont entre opérateur classique et tâche @taskDAGs, opérateurs, dépendances, branchements, sensors
Paramètres, planification, Jinja templating, macros
Gestion du temps, fuseaux, erreurs, retries, trigger rules
Connections, SQL, XComs, pipelines complets
Formation Apache Airflow — Merci !